
UNICA/UNISS FPGA-based HMPSoCs accelerators
| ID: R1 | Licence: 3-clause BSD | Owner: UNICA UNISS | Contacts: francesca.palumbo@unica.it francesco.ratto@unica.it claudio.rubattu@uniss.it |
| Short Description | HMPSoCs FPGA-based accelerators leveraging on open-source architectural templates, and exploiting coarse-grained reconfigurable (CGR) approaches for edge computation. |
| Require | – RTL description of the CGR accelerator and the RTL co-processor template – Programming tables – APIs All these inputs are derivable with the MDC tool that is part of MYRTUS DPE. |
| Provide | Acceleration infrastructure at the edge. |
| Input | Binary files for the CGR coprocessor (configuration bitstream), software application instrumented with the APIs to utilize the co-processing unit. |
| Output | Heterogeneous and hardware-accelerated execution of the application. |
| MYRTUS layer | Edge |
| TRL@M0 | 3 |
| TRL@M36 | 5 |
General description
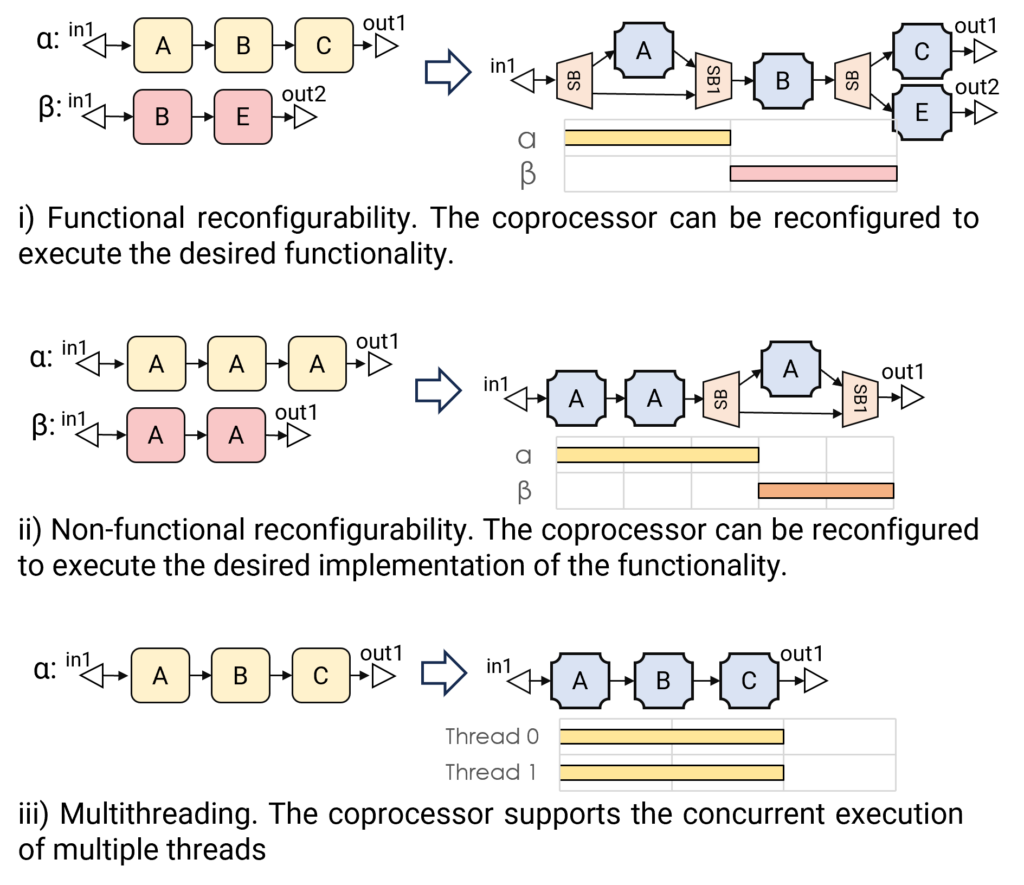
Dataflow-based CGR accelerators can be used to achieve multi-tasking execution at the edge, which can be classified as functional multi-tasking, or trade-off-oriented multi-tasking, depicted in Figure 1. The same dataflow-based approach has been used also to implement AI acceleration at the edge leveraging a streaming approach [1].
MYRTUS Extension/Contribution
At the architectural level, it is expected that these accelerators will evolve in different manners. First of all the multi-tasking approach will be extended to support a combination of multi-tasking and multi-threading, see Figure 1, where needed.
Moreover, the reconfiguration capabilities at the base of the CGR approaches are intended to be exploited to support approximate computing in the context of AI acceleration at the edge. Currently a first version of an adaptive inference engine following this approach has been made available for a simple MINST classification example [2].
Last, but not least, leveraging the heterogeneity of the chosen reference target, a customized version of the Abinsula Yocto-based Embedded Linux Distribution (Ability) is under development to allow:
- edge-fog connection: to control/monitor the edge device through database access based on REST APIs;
- accelerator management: mainly for the effective execution of the accelerator with FPGA block drivers and specific runtime manager;
- accelerator monitoring: routines and drivers related to the measures of the required metrics (i.e., power consumption, execution time, etc.);
- container orchestration: support for a lightweight version of kubernetes in order to receive and execute the application container in the form of software and hardware use case functionalities.
Plans and Expectation
Assessment Plan@M18:
Extensive lab assessment on traditional edge computing kernels, including (but not limited to) AES encryption/decryption, FFT, and video/Image processing kernels, will be carried out for the multi-threaded and multi-tasking accelerators.
The AI at the edge capabilities will be assessed wrt common classification problems starting from MNIST and CIFAR-10.
In general, metrics to be extracted will certainly involve processing latency, and power measurements, plus the accuracy for the AI at the edge accelerators, and the communication latency to connect to ABI SenseIQ .
Expected Results@M18:
Availability of the fog layer connection support.
The accuracy of the AI at the edge accelerators, in the common classification problems, is expected to be in line with the other SoA approaches.
Latency, throughput, and power improvements are case-specific, but we expect that the usage of HW-based edge acceleration approaches will allow us to save at least 10x latency reduction (with respect to the embedded ARM cores) and to reach 20-30% of power dissipation reduction.
References
- [1] Ratto, F., Máinez, Á.P., Sau, C. et al. An Automated Design Flow for Adaptive Neural Network Hardware Accelerators. J Sign Process Syst 95, 1091–1113 (2023). https://doi.org/10.1007/s11265-023-01855-x
- [2] F. Manca, F. Ratto, F. Palumbo ONNX-to-Hardware Design Flow for Adaptive Neural-Network Inference on FPGAs, to appear in Proceedings of the XXIV International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation (SAMOS), June 29 – July 4, 2024 [Online]. Available: https://zenodo.org/records/13918433
- MDC Tool, to derive this types of accelerators, is available here: https://github.com/mdc-suite/mdc/wiki