

UPM CGRA Compilation Framework
| ID: R21 | Licence: GPL-3.0 licence | Owner: UPM | Contacts: joseandres.otero@upm.es alfonso.rodriguezm@upm.es |
| Short Description | The multigrain reconfigurable CGRA requires compilation support to generate the CGRA configuration bitstream from the user’s application code. |
| Key features | Code compilation for its execution on the CGRA [1] [2]. |
| Require | Application code with the indication of the section of code susceptible to be offloaded on the CGRA accelerator. |
| Provide | Configuration binary for the multi-grain CGRA. |
| Input | – Application code (C/C++). – Description and parameters of the CGRA. – Optimization goals and expected metrics for the CGRA. |
| Output | – Configuration binary for the CGRA. |
| User | – Embedded System developers, with application programming skills. Hardware knowledge is not required. |
| Benefits for the user | – Automatic generation of accelerators with minor intervention from the users. This implies higher energy efficiency and throughput, with minor design costs. |
| Position in the MYRTUS DPE | Step 3 – Node Level Optimization |
| TRL@M0 | 2-3 |
| TRL@M36 | 4-5 |
General description
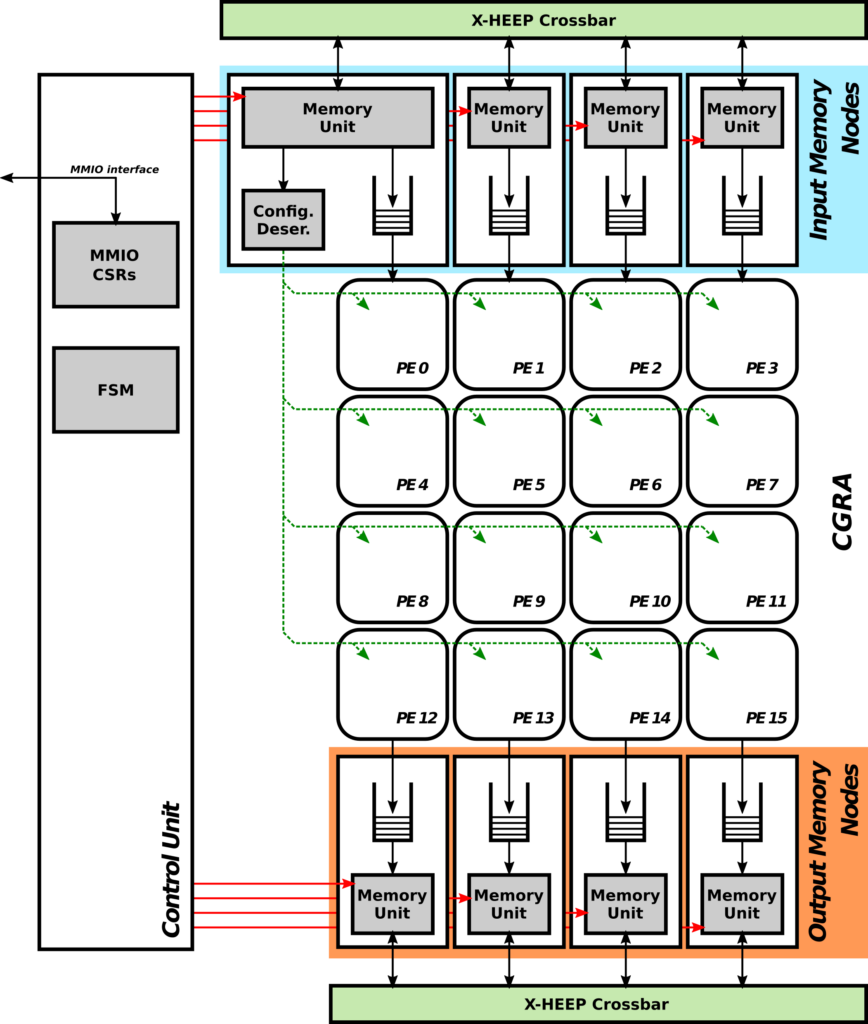
Based on MLIR, this compiler will generate configuration bitstreams for the CGRA (acting as a tightly-coupled domain-specific accelerator), in an automated manner for the user, without requiring the design of custom logic. This will allow the automatic generation of hardware accelerators in the edge without additional effort for the user. Moreover, run-time SW-to-HW computing offloading mechanisms will be incorporated to automatically extract application parallelism combined with run-time profiling/tracing to enable adaptive/speculative acceleration deployment
Role in the MYRTUS DPE
This compiler will allow users to deploy computing-intensive sections of code on the CGRA, without further user’s intervention. This enables the automatic generation of the compilers, and the potential adaptation of the architecture to multiple and different operation points, differing in the use of resources versus the achieved throughput. Based on MLIR, as part of the DPE, the compiler will enable the production of adaptable WL implementations to be executed on the computing continuum infrastructure.
MYRTUS Extension/Contribution
The original compilation framework existing for this multi-grain CGRA relied on LLVM with limited automatic parallelization capabilities. LLVM is less extensible than MLIR, and presents portability limitations. Moreover, run-time SW-to-HW computing offloading mechanisms will be incorporated to automatically extract application parallelism combined with run-time profiling/tracing to enable adaptive/speculative acceleration deployment.
Plans and Expectation
Assessment Plan@M18:
First demonstration of the compilation flow on the CGRA architecture described in R2.
Expected Results@M18:
First version of the toolchain, without the feature to automatically extract application parallelism.
References
- [1] Vázquez, D., Rodríguez, A., Otero, A., & de la Torre, E. (2022, November). Extending RISC-V Processor Datapaths with Multi-Grain Reconfigurable Overlays. In 2022 37th Conference on Design of Circuits and Integrated Circuits (DCIS) (pp. 01-06). IEEE.
- [2] https://github.com/des-cei/cgra_gen